我们首先要导入selenium里的webdriver包,然后创建一个浏览器对象,使用get()方法打开网页地址,然后就可以模拟我们用户在浏览器的操作了。根据元素的xpath路径查找元素,并返回第一个匹配的元素。根据元素的class...
”python爬虫 谷歌 自动化pythonselenium“ 的搜索结果
Python网络爬虫之 selenium学习,.py文件与谷歌浏览器驱动程序。
本文涉及了selenium在爬虫中的应用,包括定位元素,节点操作,添加cookie,反屏蔽等常用操作以及seleium中部分API源码分析

围绕 Selenium 库展开讲解如何使用自动化工具操作浏览器。
本人亲自原创制作python自动化selenium爬虫boss直聘源各个城市招聘数据源码,基于Selenium和谷歌浏览器,旨在帮助爬虫招聘数据。 使用Selenium和谷歌浏览器的方式,使得你的爬虫能够模拟人类的操作行为,实现更高效...
一文带你了解Python爬虫(一)——基本原理介绍 一文带你了解Python爬虫(二)——四种常见基础爬虫方法介绍 之所以把selenium爬虫称之为可视化爬虫 主要是相较于前面所提到的几种网页解析的爬虫方式 selenium爬虫...
本笔记为记录在linux环境下运行基于python的selenium爬虫自动化脚。适合有一定python基础的编程人员查看。以及遇到的各种问题的解决办法



偶尔的一次复习一下爬虫
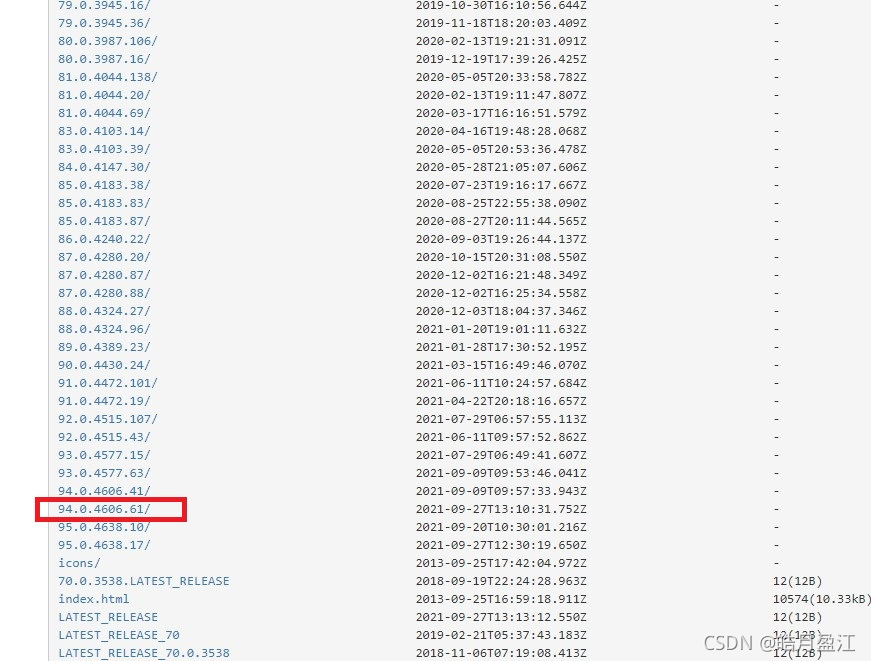

from selenium import webdriver path = "C:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe" driver = webdriver.Chrome(executable_path=path) driver.get( 'https://wwwxxxx.com/') ...
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由...

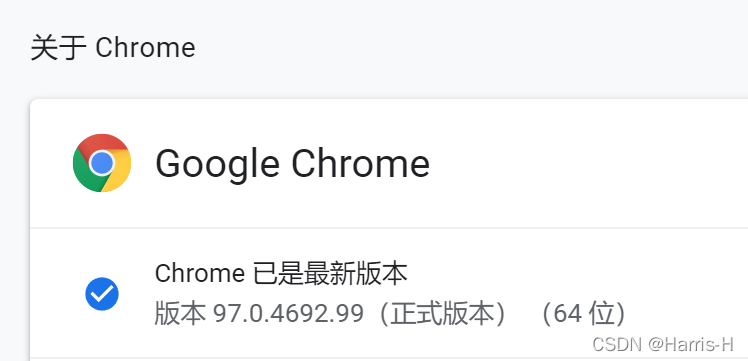
一、概述我们要先安装selenium这个库,使用pip install selenium 命令安装,selenium这个库相当于机器模仿人的行为去点击浏览器上的元素,这时我们要用到一个浏览器的驱动(这里我用的是谷歌浏览器)。二、安装驱动...
【爬虫案例】动态地图里的数据如何抓取:以全国PPP综合信息平台网站为例 http://mp.weixin.qq.com/s/BXWTf5hmq8vp91ZvgaphEw【爬虫案例】动态页面的抓取!以东方财富网基金行情数据为例 ...
Selenium 4是一个流行的网页自动化测试工具,为测试人员和开发人员提供了一系列强大的功能来模拟用户在网页上的操作。这个版本相较之前版本语法上发生了一系列变化 引入了一些新特性和改进,比如改进的WebDriver接口...

Python和Selenium是很强大的爬虫工具,可以用于自动化地模拟浏览器行为,从网页中提取数据。下面是一个简单的使用Python和Selenium进行爬虫的案例。

2.找到输入框,输入selenium。运行一下,效果杠杠的(*^▽^*)写一个自动打开百度网页的程序,3.点击“百度一下”进行搜索。安装Chromedrive。打开chromdriver。安装selenium。
在做资料分析,训练模型时,常常需要大量的资料来帮助建模,如何自动化又快速的搜集大量资料也很难。...另外还有很多优秀的框架,像是pyspider及scrapy等等简介文章使用Python常用的自动化工具—...
3.进入百度界面-https://www.baidu.com/#1.导入谷歌公司selenium项目的webdriver驱动。#2.打开对应的浏览器-谷歌。#4.输入yandex。
推荐文章
- 手写一个SpringMVC框架(有助于理解springMVC) 侵立删_springmvc可以用来写安卓后端吗-程序员宅基地
- 线性判别分析LDA((公式推导+举例应用))_lda推导-程序员宅基地
- C# 结构体(Struct)精讲_c# struct-程序员宅基地
- 支付宝Wap支付你了解多少?_阿里wap支付-程序员宅基地
- Java计算器编写,实现循环输入_java简易计算器可使用户多次输入-程序员宅基地
- 【多维Dij+DP】牛客小白月赛75 D-程序员宅基地
- Android之内存优化与OOM-程序员宅基地
- Azure Machine Learning - 视频AI技术_azure ai 視頻索引器-程序员宅基地
- 个人知识管理软件使用感受-程序员宅基地
- WWDC2019 ------深入理解App启动_wwdc app启动-程序员宅基地